
In the realm of natural language processing (NLP), the Transformer model has emerged as a game-changer, transforming how we approach sequence transduction tasks such as machine translation. Traditionally dominated by recurrent neural networks (RNNs) and convolutional neural networks (CNNs), sequence transduction has seen remarkable advancements with the introduction of the Transformer, a model that relies solely on attention mechanisms.
The Transformer: A New Paradigm
The Transformer model, proposed by Vaswani et al., revolutionizes the traditional encoder-decoder architecture used in sequence transduction. Unlike RNNs and CNNs that process sequences with recurrent and convolutional operations, the Transformer leverages self-attention mechanisms to model dependencies across the entire sequence, allowing for significant parallelization and faster training times.
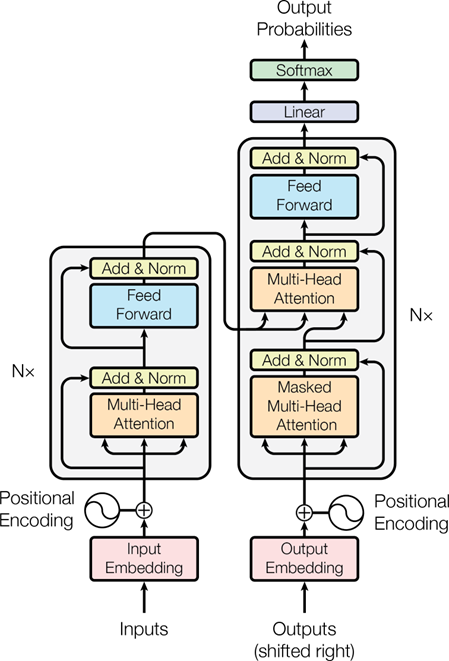
Encoder and Decoder Stacks
The Transformer model is divided into two main components: the Encoder and the Decoder.
- Encoder: The encoder processes the input sentence and generates a sequence of representations. Each encoder layer consists of a multi-head self-attention mechanism followed by a feed-forward neural network.
- Decoder: The decoder generates the output sequence (e.g., translated text) based on the encoder’s representations and previous outputs. It also uses multi-head self-attention and feed-forward layers.
The Magic of Self-Attention
At the heart of the Transformer model lies the self-attention mechanism, a groundbreaking concept that enables the model to understand the relationships between all words in a sentence, regardless of their position. Unlike traditional models that process words sequentially, Transformers consider the entire sentence at once. This holistic view is what empowers them to grasp complex linguistic nuances.
Imagine you’re reading a book. As you progress through the pages, you naturally keep track of various characters, plot points, and themes. The self-attention mechanism works similarly. It assigns attention weights to every word in the sentence, highlighting the importance of each word in relation to others. This means that the model can understand not just who has the book, but also the broader context of why and how the book is relevant.
How Does Self-Attention Work?
To make this concept more concrete, let’s break down the self-attention mechanism mathematically.
- Input Representation: First, each word in the input sentence is converted into a numerical representation, known as an embedding. This is done using a tokenizer, which maps words to unique vectors.
- Query, Key, and Value Vectors: For each word, three vectors are created: Query (Q), Key (K), and Value (V). These vectors are obtained by multiplying the embedding with three different weight matrices.
Q = XWQ, K = XWK,V = XWV
Here, X is the input embedding, and WQ, WK and WV are weight matrices learned during training. - Attention Scores: The relevance of each word to the others is calculated using the dot product of the Query vector of one word with the Key vectors of all words, followed by a softmax function to obtain normalized attention scores.
Attention(Q,K,V) = softmaxQKT/dkV
Where dk is the dimension of the Key vectors, used for scaling.
- Output Calculation: These attention scores are then used to compute a weighted sum of the Value vectors, producing the final output for each word.
Multi-Head Attention
The Transformer doesn’t rely on a single set of attention scores. Instead, it employs multi-head attention, where multiple sets of Query, Key, and Value vectors are used in parallel. Each set, or “head,” captures different aspects of the relationships between words. This allows the model to simultaneously consider various linguistic features, such as syntax and semantics.
Multi-head attention allows the model to jointly attend to information from different representation subspaces. Instead of performing a single attention function, multi-head attention runs several attention mechanisms in parallel, projecting the concatenated outputs back into the expected dimension:
MultiHead(Q,K,V)=Concat(head1,head2,…,headh)WO
Where each head is computed as:
headi = Attention(QWiQ,KWiK,VWiV)
Positional Encoding
Since the Transformer lacks the sequential nature of RNNs, it uses positional encoding to retain the order of the input sequence. This encoding adds sinusoidal patterns to the input embeddings, enabling the model to learn positional relationships effectively. The positional encoding is defined as:
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
Where:
- pos is the position.
- i is the dimension index.
- dmodel is the dimension of the embeddings.
Advantages of the Transformer
- Parallelization: Unlike RNNs, the Transformer allows for parallel processing of sequence elements, significantly reducing training times.
- Scalability: The model can handle longer sequences with ease, making it suitable for tasks involving extensive texts.
- Performance: The Transformer achieves state-of-the-art results on machine translation tasks, outperforming previous models in terms of BLEU scores.
Practical Applications
The power of Transformer models extends far beyond theoretical elegance. They have revolutionized numerous applications, including:
- Machine Translation: Transformers excel in translating text from one language to another by understanding the context and relationships between words in both languages.
- Text Summarization: By capturing the essence of lengthy documents, Transformers can generate concise and coherent summaries.
- Sentiment Analysis: These models can accurately gauge the sentiment of a text, whether it’s a product review or a social media post.
- Question Answering: Transformers can understand and generate accurate answers to natural language questions by comprehending the context of the input text.
Conclusion
The Transformer model, with its self-attention mechanism and innovative architecture, has transformed the landscape of natural language processing. By capturing intricate relationships between words and considering the entire context, Transformers have set new benchmarks in language understanding and generation. Whether you’re a seasoned data scientist or a curious learner, understanding the magic of Transformers opens up a world of possibilities in the realm of AI and NLP.